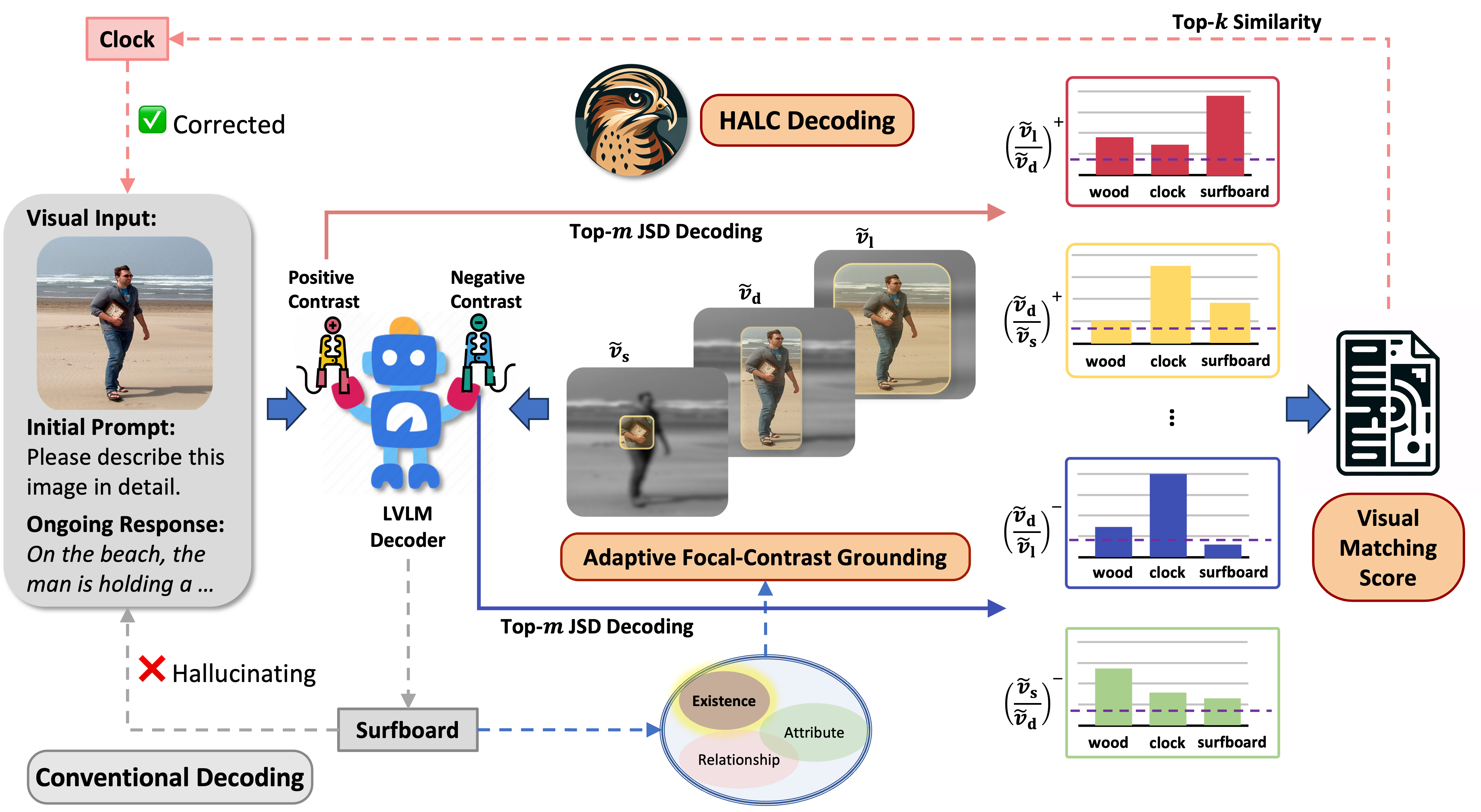
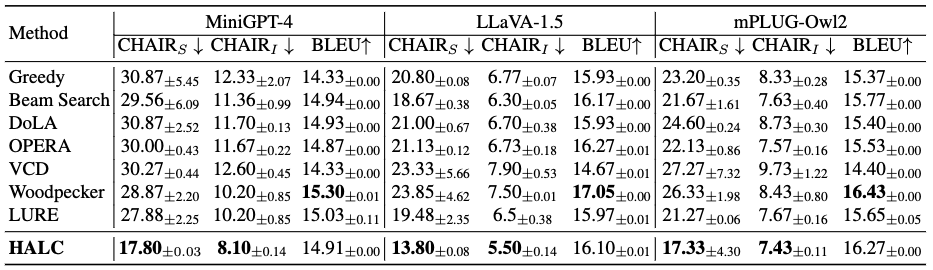
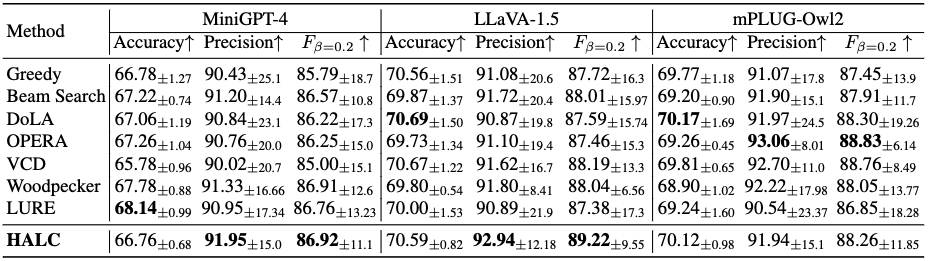
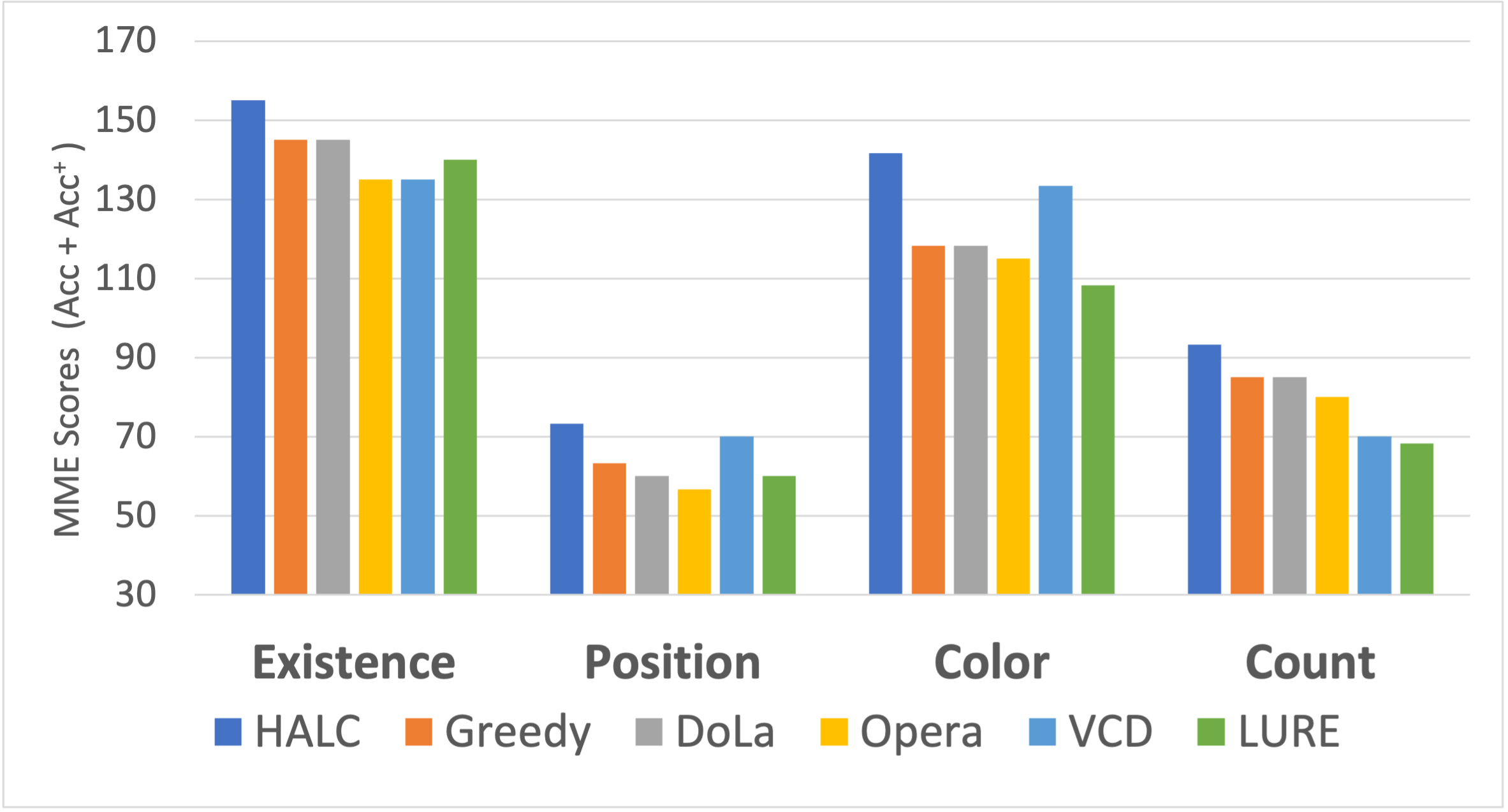
While large vision-language models (LVLMs) have demonstrated impressive capabilities in interpreting multi-modal contexts, they invariably suffer from object hallucinations (OH). We introduce HALC, a novel decoding algorithm designed to mitigate OH in LVLMs. HALC leverages distinct fine-grained optimal visual information in vision-language tasks and operates on both local and global contexts simultaneously. Specifically, HALC integrates a robust auto-focal grounding mechanism (locally) to correct hallucinated tokens on the fly, and a specialized beam search algorithm (globally) to significantly reduce OH while preserving text generation quality. Additionally, HALC can be integrated into any LVLMs as a plug-and-play module without extra training. Extensive experimental studies demonstrate HALC’s effectiveness in reducing OH, outperforming state-of-the-arts across four benchmarks. Code is released here.
@article{chen2024halc,
title={HALC: Object Hallucination Reduction via Adaptive Focal-Contrast Decoding},
author={Chen, Zhaorun and Zhao, Zhuokai and Luo, Hongyin and Yao, Huaxiu and Li, Bo and Zhou, Jiawei},
journal={arXiv preprint arXiv:2403.00425},
year={2024}
}